| |
|
| |
Описание для автора не найдено
|
|
| |
|
|
| |
|
| |
Понимание XML Schema
Автор: Aaron Skonnard, DevelopMentor
Перевод: Шатохина Надежда(sna@uneta.org), Ukraine .Net
Alliance (http://www.uneta.org)
Март 2003
Применяется к:
Системы типов
Язык описания XML Schema (XSD)
Разработка Web сервисов
Обзор:
XML Schema создана, чтобы играть
центральную роль в будущем обработки XML, особенно в Web сервисах, в которых она
является одним из фундаментальных принципов, на которых построены высшие уровни
абстракции. В этой статье детально описано, как использовать Язык описания XML
Schema.
Введение
Типы данных: значение и лексические пространства
Определение типов в пространствах имен
Определение простых типов
Определение составных типов
Размещение и управление схемами
Заключение
Введение
1 + 2 = ?
В программном обеспечении информацию, необходимую для ответа на такой вопрос,
предоставляет система типов. Языки программирования используют системы типов для
упрощения задачи создания качественного кода. Система типов определяет набор
типов и операций, которыми разработчики могут оперировать в своих программах.
Тип определяет пространство значений, иначе говоря, ряд возможных значений.
Например, если принять, что тип приведенных выше операндов числовой, ответ мог
бы быть «3», но если их тип – строка, ответ может быть «12», в зависимости от
того, как определен оператор +.
Одним из главных преимуществ системы типов является тот факт, что компиляторы
могут использовать ее для определения наличия дефектов в коде еще до выполнения,
сразу предупреждая возникновение широкого диапазона возможных ошибок.
Компиляторы также используют информацию системы типов при генерировании кода для
операций над данным типом. Кроме того, и компиляторы, и системы выполнения
сильно полагаются на системы типов при распределении памяти для конкретного
типа, когда он используется, позволяя разработчикам не тратить время на такие
утомительные вещи.
Многие языки программирования и среды выполнения также делают возможным
программно проверять информацию о типе во время выполнения. Это позволяет
разработчикам обращаться к любому экземпляру, задавать вопросы о его типовых
характеристиках и на основе полученных ответов принимать решения. Такую технику
динамической проверки информации о типе обычно называют отражением (reflection).
Отражение играет главную роль в основных современных управляемых средах
программирования, таких как Microsoft® .NET Framework и Java, в которых
виртуальная машина (например, общеязыковая среда выполнения или JVM)
обеспечивает дополнительные сервисы, необходимые большинству программ, такие как
безопасность, сборка мусора, сериализация, удаленный вызов метода и даже
интеграцию Web сервиса, эффективно уменьшая количество задач, о которых должны
беспокоиться разработчики при создании кода.
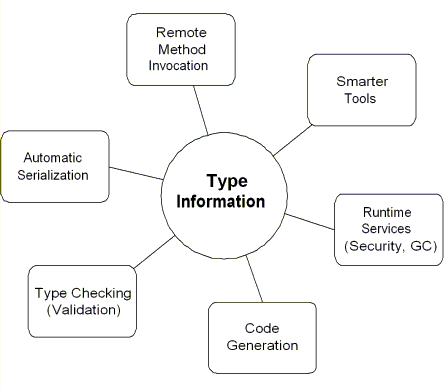
Рисунок 1. Преимущества информации о типе Хорошо описанная система типов наряду с отражением также делает возможным
создавать лучшие инструментальные средства для работы с языком программирования.
Разработчики быстро привыкли к таким вещам как Microsoft® Intellisense®,
автоматическое дополнение кода и таким удобным красным тильдам, которые
существенно ускоряют процесс разработки. В общем, хорошая система типов
предлагает много интересных преимуществ (см. Рисунок 1), большинство из которых
легко принять как должное, но которых очень не хватает в случае их
отсутствия.
Хорошим примером языка программирования, в котором не хватает чувствительной
системы типов, является XML 1.0. Без системы типов информация, находящаяся в
документе XML 1.0, может интерпретироваться только как текст. Поэтому
разработчики должны знать о " действительном типе" заранее, чтобы иметь
возможность осуществить необходимые приведения в своем коде.
Язык описания XML Schema (XSD) предоставляет систему типов для сред обработки
XML. В двух словах, XML Schema делает возможным описание типов, которые вы
собираетесь использовать. На документ XML, соответствующий типу XML Schema,
часто ссылаются как на экземпляр документ, что очень похоже на традиционные
объектно-ориентированные (ОО) отношения между классами и объектами (см. Рисунок
2). Это концептуально отличается от принципов работы Определений типа документа
(Document Type Definitions (DTD)), которые предлагают большую гибкость при
преобразовании в традиционный язык программирования или системы типов баз
данных. В этих средах XML Schema в значительной степени сокращает использование
DTD.
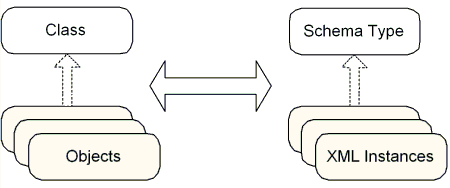
Рисунок 2. Объектно-ориентированные и XML отношения XML Schema способна обеспечить все преимущества, приведенные на Рисунке 1, но
только полностью XML-центричным способом. Логический XML документ, содержащий
информацию о типах XML Schema, обычно называют информационное множество после
проверки корректности схемы (PSVI). PSVI делает возможным осуществление
динамического отражения на базе XML Schema, точно так же как и в других средах
программирования. В общем, XML Schema подготовлена для того, чтобы в будущем
играть центральную роль в обработке XML, особенно в Web сервисах, в которых она
служит одним из фундаментальных принципов, на которых строятся высшие уровни
абстракции. Далее в этой статье более детально описано, как использовать Язык
описания XML Schema.
Типы данных: значение и лексические пространства
XML Schema предоставляет набор встроенных типов данных, которые могут
использоваться разработчиками для включения текста (см. рисунок в W3C XML Schema Part 2: Datatypes Web page
(http://www.w3.org/TR/xmlschema-2/#built-in-datatypes)). Все эти
типы помещены в пространство имен http://www.w3.org/2001/XMLSchema
(http://www.w3.org/2001/XMLSchema). Каждый тип имеет
определенную область значений. Область значений типа – это просто ряд значений,
которые могут использоваться в экземпляре данного типа.
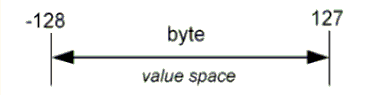
Рисунок 3. Область значений типа Byte Например, XML Schema предоставляет встроенный тип byte,
область значений которого от -128 до 127. Другой пример – тип
boolean, чья область значений намного проще и состоит только из
двух значений: true и false. В общем, у вас есть возможность
выбирать из сорока четырех встроенных типов, каждый из которых имеет различные
области значений, предназначенные для удовлетворения широкого диапазона нужд при
моделировании данных.
На Рисунке 4 показано, что многие встроенные типы определяются как
подмножество области значений другого типа. Это явление также известно как
наследование по ограничению (derivation by restriction).
Например, область значений byte является подмножеством области
значений short, которая является подмножеством области значений
int, которая, в свою очередь, есть подмножество области
значений long и т.д. Следовательно, основная теория множеств
говорит о том, что экземпляр наследуемого типа также является действительным
экземпляром любого из его типов-родителей. (Строго говоря, они сами являются
подмножествами anySimpleType).
Хотя языки программирования используют информацию об области значений, для
определения того, сколько памяти понадобится для представления значений, иногда
и разработчикам надо побеспокоиться о представлении их как текста. С XML,
однако, можно игнорировать тот факт, что экземпляры, скорее всего, будут
сериализованы в файл XML 1.0, требующий лексического представления значения.
Если бы каждый обработчик XML Schema должен был бы принимать решение о том, как
сделать это, независимо, возможность взаимодействовать была бы вскоре утрачена.
Поэтому, кроме определения области значений каждого типа, XML Schema также
определяет и их допустимые лексические представления.
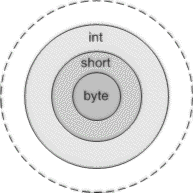
Рисунок 4. Подмножества типа Например, логическое значение true может быть представлено или как "true",
или как "1", в то время как false можно представить как "false" или как "0".
Значение 10 типа double может быть представлено как "10", "10.0", "10.0000" или
даже "0.01E3". А дата January 1, 2003 может быть представлена как "2003-01-01".
Стандартизация лексического формата (и любых возможных вариаций) для каждого
типа дает возможность разработчикам в коде иметь дело исключительно со
значениями, опуская сложности их сериализации.
Определение типов в пространствах имен
Кроме предоставления встроенных типов, во многих языках программирования
разработчикам разрешено определять свои собственные типы, обычно называемые
определенными пользователем типами (UDT). При определении UDT большинство языков
программирования также позволяют вам определять для них и пространство имен,
чтобы не путать их с другими UDT, случайно использующими такое же имя. Подробно
о работе пространства имен XML см. в Understanding XML
Namespaces
(http://msdn.microsoft.com/webservices/understanding/xmlfundamentals/default.aspx?pull=/library/en-us/dnxml/html/xml_namespaces.asp).
На Рисунке 5 сравнивается определение пространства имен C# и XML Schema. Как
можно заметить, XML Schema также поддерживает определение типов в пространстве
имен.
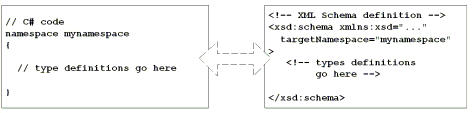
Рисунок 5. Определение типов в пространствах имен Элемент xsd:schema определяет то, что находится в
пространстве имен, а атрибут targetNamespace определяет имя
пространства имен. Например, следующий шаблон XML Schema определяет новое
пространство имен http://example.org/publishing:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://example.org/publishing"
xmlns:tns="http://example.org/publishing"
>
<!-- type definitions -->
<xsd:simpleType name="AuthorId">
<!-- define value space details here -->
...
</xsd:simpleType>
<xsd:complexType name="AuthorType">
<!-- define structural details here -->
...
</xsd:complexType>
<!-- global element/attribute declarations -->
<xsd:element name="author" type="tns:AuthorType"/>
<xsd:attribute name="authorId" type="tns:AuthorId"/>
...
</xsd:schema>
Считается, что все, что помещено в элемент xsd:schema (как
прямой потомок), является глобальным, и, следовательно, автоматически
ассоциируется с целевым пространством имен. В предыдущем примере в пространство
имен включены AuthorId, AuthorType,
author и authorId. В результате, когда бы вы
не обращались к одному из этих элементов в вашей схеме, вы должны использовать
имя, определенное пространством имен.
Чтобы использовать имя, определенное пространством имен, вам понадобится
описание другого пространства имен, которое преобразовывает в значение схемы
targetNamespace. Для этой цели служит описание пространства
имен 'tns', приведенное выше. Следовательно, где бы мне ни
понадобилось бы обратиться к чему-то, что я определил в своей схеме, я могу
использовать имя с приставкой 'tns', как показано в
примере.
В элементе xsd:schema вы можете определить два класса типов:
простые типы (используя xsd:simpleType) и составные типы
(используя xsd:complexType). Простые типы могут быть назначены
только для текстовых элементов и атрибутов, т.к. они не определяют структуру, а
скорее, области значений. Элемент с дополнительной структурой, например, такой,
который имеет атрибуты или дочерние элементы, должен быть определен как
составной тип.
Кроме типа, вы можете определить в схеме глобальные элементы (используя
xsd:element) и атрибуты (используя
xsd:attribute) и назначить им тип. В предыдущем примере я
определил глобальный элемент author и глобальный атрибут
authorId. Поскольку эти структуры также глобальные, они должны
быть определены целевым пространством имен, когда я использую их в экземплярах
документов. Следующий XML документ содержит экземпляр определенного ранее
элемента author:
<x:author xmlns:x="http://example.org/publishing">
<!-- structure determined by complexType definition -->
...
</x:author>
И следующий XML документ содержит глобальный атрибут
authorId:
<!-- authorId value constrained by simpleType definition -->
<publication xmlns:x="http://example.org/publishing"
x:authorId="333-33-3333"/>
Используя атрибут type из пространства имен
http://www.w3.org/2001/XMLSchema-instance, также можно явно
назначить тип элемента в экземпляре документа. В этом пространстве имен есть
небольшое количество атрибутов, которые могут использоваться только в
экземплярах документа. Использование атрибута типа подобно преобразованию типов
в некоторых языках программирования. В следующем примере элементу
genericId (который не был определен в схеме) явно назначается
тип AuthorId:
<genericId
xmlns:x="http://example.org/publishing"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:type="tns:AuthorId"
>333-33-3333</genericId>
Обратите внимание, что AuthorId – это тот же тип, который мы
назначили глобальному атрибуту authored, показанному выше. Это
иллюстрирует то, что вы можете присваивать простые типы как атрибутам, так и
текстовым элементам, чтобы соответственным образом ограничить их значения. Также
важно отметить, что техника xsi:type назначения типов применима
только к элементам, но не к атрибутам.
Определение простых типов
Большинство языков программирования позволяют разработчикам только
компоновать различные встроенные типы в некоторого рода структурированные типы,
но они не дают возможности определять новые простые типы, имеющие определенные
пользователем области значений. С этой точки зрения XML Schema отличается,
потому что она позволяет пользователям определять собственные специальные
простые типы, области значений которых являются подмножествами предопределенных
встроенных типов.
Вы определяете новый простой тип, используя элемент
xsd:simpleType, как показано ранее. В элементе
xsd:simpleType вы определяете базовый тип, чью область значений
вы хотите ограничить (используя элемент
xsd:restriction). В элементе xsd:restriction
вы определяете, как именно вы хотите ограничивать базовый тип, сужая один или
более из его аспектов (facets). Например, следующие простые
типы ограничивают области значений xsd:double и
xsd:date до более определенных диапазонов, используя аспекты
xsd:minInclusive и xsd:maxInclusive:
...
<xsd:simpleType name="RoyaltyRate">
<xsd:restriction base="xsd:double">
<xsd:minInclusive value="0"/>
<xsd:maxInclusive value="100"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="Pubs2003">
<xsd:restriction base="xsd:date">
<xsd:minInclusive value="2003-01-01"/>
<xsd:maxInclusive value="2003-12-31"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:element name="rate" type="tns:RoyaltyRate"/>
<xsd:element name="publicationDate" type="tns:Pubs2003"/>
...
Следующие документы содержат корректные экземпляры определенных выше
документов:
<x:rate xmlns:x="http://example.org/publishing">17.5</x:rate>
<x:publicationDate xmlns:x="http://example.org/publishing"
>2003-06-01</x:publicationDate>
XML Schema определяет аспекты, доступные для каждого типа (см. Таблицу 1).
Большинство аспектов неприменимы ко всем типам (некоторые имеют смысл только в
определенных типах). Большинство аспектов ограничивают область значений типа, в
то время как шаблонный аспект ограничивает лексическую область типа. Ограничения
значения или лексической области косвенно ограничивают друг друга. Предыдущие
примеры ограничивали область значений базового типа, а приведенные далее —
ограничивают лексическую область строки с помощью регулярных выражений:
...
<xsd:simpleType name="SSN">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\d{3}-\d{2}-\d{4}"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="PublisherAssignedId">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\d{2}-\d{8}"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="Phone">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\(\d{3}\)\d{3}-\d{4}"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:element name="authorId" type="tns:SSN"/>
<xsd:element name="pubsAuId" type="tns:PublisherAssignedId"/>
<xsd:element name="phone" type="tns:Phone"/>
...
Следующие документы содержат корректные экземпляры определенных выше
элементов:
<x:authorId xmlns:x="http://example.org/publishing"
>123-45-6789</x:authorId>
<x:pubsAuId xmlns:x="http://example.org/publishing"
>01-23456789</x:pubsAuId>
<x:phone xmlns:x="http://example.org/publishing"
>(801)390-4552</x:phone>
Корректным экземпляром данного типа считаются только строки, соответствующие
регулярным выражениям (определенными в шаблонном аспекте).
| Facet элемент |
Описание |
| xsd:enumeration |
Определяет фиксированное значение, с которым должен совпадать
тип. |
| xsd:fractionDigits |
Определяет максимальное количество десятичных знаков справа от
десятичной точки. |
| xsd:length |
Определяет количество символов в строковом типе, количество байтов в
двоичном типе или количество элементов в списочном типе. |
| xsd:maxExclusive |
Определяет исключающую верхнюю границу области значений типа. |
| xsd:maxInclusive |
Определяет включающую верхнюю границу области значений типа. |
| xsd:maxLength |
Определяет максимальное количество символов в строковом типе,
максимальное количество байтов в двоичном типе или максимальное количество
элементов в списочном типе. |
| xsd:minExclusive |
Определяет исключающую нижнюю границу области значений типа. |
| xsd:minInclusive |
Определяет включающую нижнюю границу области значений типа. |
| xsd:minLength |
Определяет минимальное количество символов в строковом типе,
минимальное количество байтов в двоичном типе или минимальное количество
элементов в списочном типе. |
| xsd:pattern |
Определяет шаблон, основанный на регулярном выражении, с которым
должен совпадать тип. |
| xsd:totalDigits |
Определяет максимальное количество десятичных знаков для типов,
унаследованных от number. |
| xsd:whiteSpace |
Определяет правила нормирования пробелов. |
Таблица 1. Аспекты
Другой интересный аспект - xsd:enumeration, который дает
возможность ограничивать область значений до списка перечислимых значений. В
следующих примерах область значений xsd:NMTOKEN ограничивается
до четырех определенных перечислимых значений:
...
<xsd:simpleType name="PublicationType">
<xsd:restriction base="xsd:NMTOKEN">
<xsd:enumeration value="Book"/>
<xsd:enumeration value="Magazine"/>
<xsd:enumeration value="Journal"/>
<xsd:enumeration value="Online"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:element name="pubType" type="tns:PublicationType"/>
...
Следующий документ содержит корректный экземпляр элемента, определенного
выше:
<x:pubType xmlns:x="http://example.org/publishing"
>Online</x:pubType>
| Производный элемент |
Описание |
| xsd:restriction |
Новый тип является ограничением существующего типа, т.е. он имеет
более узкий ряд допустимых значений. |
| xsd:list |
Новый тип является разделенным пробелами списком другого простого
типа. |
| xsd:union |
Новый тип является объединением двух или более других простых
типов. |
Таблица 2. Техника построения простого типа
Кроме ограничения области значений типа, можно создать новые простые типы,
являющиеся списками или объединениями других простых типов.
Для этого вы используете не xsd:restriction, а элементы
xsd:list или xsd:union (см. Таблицу 2).
Используя xsd:list, вы, по существу, определяете разделенный
пробелами список значений из определенной области значений. Не стоит и упоминать
о том, что при использовании xsd:list или
xsd:union нет иерархии наследования, как при использовании
xsd:restriction, поэтому в этих случаях не выполняется
совместимость типов. В следующем примере новый тип AuthorList
определяется как список SSN значений.
...
<xsd:simpleType name="AuthorList">
<xsd:list itemType="tns:SSN"/>
</xsd:simpleType>
<xsd:element name="authors" type="tns:AuthorList"/>
...
следующий документ содержит корректный экземпляр элемента
authors:
<x:authors xmlns:x="http://example.org/publishing"
>111-11-1111 222-22-2222 333-33-3333 444-44-4444</x:authors>
В случае использования xsd:union вы создаете новый тип,
комбинирующий множество областей значений в новую область значений. Экземпляр
типа-объединения может быть значением из любой из указанных областей значений.
Например, следующий тип AuthorId сочетает SSN область значений
с областью значений PublisherAssignedId:
...
<xsd:simpleType name="AuthorId">
<xsd:union memberTypes="tns:SSN tns:PublisherAssignedId"/>
</xsd:simpleType>
<xsd:element name="authorId" type="tns:AuthorId"/>
...
Каждый из следующих документов демонстрирует корректный экземпляр элемента
authorId:
<x:authorId xmlns:x="http://example.org/publishing"
>111-11-1111</x:authorId>
<x:authorId xmlns:x="http://example.org/publishing"
>22-22222222</x:authorId>
Поддержка XML Schema для определенных пользователем типов и, в частности,
специальных значений/лексических областей является одним из наиболее мощных
аспектов языка. Тот факт, что большинство языков программирования не
обеспечивают этого, вынуждает разработчиков решать эти вопросы в коде своих
приложений самостоятельно (обычно через механизмы установки свойств).
Способность определять специальные значения/лексические области, удовлетворяющие
вашим точным потребностям, делает возможным переместить обработку ошибок и код
проверки правильности на уровень ниже.
Определение составных типов
XML Schema делает возможным компоновать различные простые типы (или области
значений) в структуру, также известную как составной (complex)
тип. Чтобы определить новый составной тип в целевом пространстве имен
схемы, вы используете элемент xsd:complexType, как показано
здесь:
...
<xsd:complexType name="AuthorType">
<!-- compositor goes here -->
</xsd:complexType>
...
Элемент xsd:complexType содержит то, что известно как
составитель, который описывает формирование содержимого типа, также
известного как модельсодержимого. XML Schema определяет три
составителя, которые могут использоваться при описании составного типа, включая
xsd:sequence, xsd:choice и
xsd:all (см. Таблицу 3).
Составители содержат части, которые включают такие вещи, как другие
составители, описания элементов, групповые символы и типовые группы. Описания
атрибутов не считаются частями, потому что они не повторяются. Следовательно,
описания атрибутов помещаются не в составителе, а после него в конце определения
составного типа.
| Составитель |
Описание |
| xsd:sequence |
Упорядоченная последовательность содержащихся частей |
| xsd:choice |
Выбор содержащихся частей |
| xsd:all |
Все содержащиеся части в любом порядке |
Таблица 3. Составители составного типа
Описание элемента (xsd:element), возможно, наиболее часто
используемая часть. Следующий complexType, названный
AuthorType, определяет упорядоченную последовательность двух
дочерних элементов и атрибута, имеющих различные простые типы:
...
<xsd:complexType name="AuthorType">
<!-- compositor goes here -->
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="phone" type="tns:Phone"/>
</xsd:sequence>
<xsd:attribute name="id" type="tns:AuthorId"/>
</xsd:complexType>
<xsd:element name="author" type="tns:AuthorType"/>
...
Элементы и атрибуты, объявленные в элементе xsd:complexType,
считаются локальными по отношению к составному типу. Локальные элементы
могут использоваться только в пределах контекста, в котором они определены. Тут
возникает интересный вопрос: а должно ли указываться пространство имен для
локальных элементов/атрибутов в экземплярах документа. Поскольку локальные
элементы и атрибуты всегда будут содержать родительский элемент (обычно
глобальный элемент), определенный целевым пространством имен, можно согласиться,
что в этом нет необходимости. Нечто подобное происходит в большинстве языков
программирования – если вы определяете класс в пространстве имен, пространством
имен определяется только имя класса, а не его локальные члены.
Поэтому в XML Schema локальные элементы и атрибуты не должны указывать
пространство имен по умолчанию. Следовательно, корректный экземпляр элемента
author выглядит так:
<x:author xmlns:x="http://example.org/publishing"
id="333-33-3333"
>
<name>Aaron Skonnard</name>
<phone>(801)390-4552</phone>
</x:author>
Однако XML Schema делает возможным явно контролировать, должен ли данный
локальный элемент/атрибут содержать пространство имен или не должен, путем
применения атрибута формы к
xsd:element/xsd:attribute или атрибутов
elementFormDefault/attributeFormDefault к
xsd:schema, как показано ниже:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://example.org/publishing"
xmlns:tns="http://example.org/publishing"
elementFormDefault="qualified"
attributeFormDefault="qualified"
>
...
</xsd:schema>
С этой схемой следующий экземпляр будет считаться корректным (а предыдущий
экземпляр нет):
<x:author xmlns:x="http://example.org/publishing"
x:id="333-33-3333"
>
<x:name>Aaron Skonnard</x:name>
<x:phone>(801)390-4552</x:phone>
</x:author>
В большинстве случаев до тех пор, пока экземпляры согласуются со схемой, не
имеет значения, стиль какого пространства имен вы используете для локальных
элементов.
Вы также можете обращаться к описаниям глобального элемента/атрибута из
составного типа, используя атрибут ref, как показано ниже:
...
<!-- global definitions -->
<xsd:attribute name="id" type="tns:AuthorId"/>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="author" type="tns:AuthorType"/>
<xsd:complexType name="AuthorType">
<!-- compositor goes here -->
<xsd:sequence>
<!-- reference to global element -->
<xsd:element ref="tns:name"/>
<xsd:element name="phone" type="tns:Phone"/>
</xsd:sequence>
<!-- reference to global attribute -->
<xsd:attribute ref="tns:id"/>
</xsd:complexType>
...
Поскольку id и name – глобальные элементы,
они всегда должны содержать пространство имен в экземплярах документа.
Использование "ref" устанавливает, что глобальный элемент также
может использоваться в контексте AuthorType, но это не меняет
того факта, что он должен быть содержать пространство имен. Элемент
phone все еще определен локально, что означает, что можно
указывать, а можно и не указывать в экземпляре, в зависимости от используемой
формы. Таким образом, если elementFormDefault="unqualified",
корректный экземпляр может выглядеть так:
<x:author xmlns:x="http://example.org/publishing"
x:id="333-33-3333"
>
<x:name>Aaron Skonnard</x:name>
<phone>(801)390-4552</phone>
</x:author>
И теперь для немного более сложного примера, который использует вложенные
составные типы, другие составители и повторяющиеся части:
...
<xsd:complexType name="AddressType">
<xsd:all>
<xsd:element name="street" type="xsd:string"/>
<xsd:element name="city" type="xsd:string" minOccurs="0"/>
<xsd:element name="state" type="tns:State" minOccurs="0"/>
<xsd:element name="zip" type="tns:Zip"/>
</xsd:all>
</xsd:complexType>
<xsd:complexType name="PublicationsListType">
<xsd:choice maxOccurs="unbounded">
<xsd:element name="book" type="xsd:string"/>
<xsd:element name="article" type="xsd:string"/>
<xsd:element name="whitepaper" type="xsd:string"/>
</xsd:choice>
</xsd:complexType>
<xsd:complexType name="AuthorType">
<xsd:sequence>
<xsd:choice>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="fullName" type="xsd:string"/>
</xsd:choice>
<xsd:element name="address" type="tns:AddressType"/>
<xsd:element name="phone" type="tns:Phone"
minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="recentPublications"
type="tns:PublicationsListType"/>
</xsd:sequence>
<xsd:attribute name="id" type="tns:AuthorId"/>
</xsd:complexType>
<xsd:element name="author" type="tns:AuthorType"/>
...
В этом примере AuthorType включает последовательность
другого составителя, выбор, за ним следуют описания трех элементов. Типом
некоторых элементов являются другие определенные пользователем составные типы
(AddressType и PublicationsListType), которые
эффективно определяют вложенные структуры в типе. Выбор означает, что здесь
допускается появление элементов name или fullName. И, наконец,
составитель all в AddressType означает, что порядок элементов
неважен.
Обратите также внимание, что с помощью атрибутов minOccurs и
maxOccurs описание элемента phone определяет
ограничения появлений (occurrence constraints). В составном типе
ограничения появлений могут применяться к любой части. Стандартное значение для
каждой части – 1, это означает, что данная часть должна появиться в указанном
месте именно один раз. Определение minOccurs="0" делает данную
часть необязательной, а определение maxOccurs="unbounded"
позволяет бесконечные повторения части. Если пожелаете, вы можете задать также
произвольные границы, например, minOccurs="3" maxOccurs="77".
Использование ограничений появлений по отношению к составителю применяется ко
всей группе, как к целому (обратите внимание на
PublicationsListType, который применяет ограничения появлений к
выбору). Здесь приведен пример корректного экземпляра нашего нового
AuthorType:
<x:author xmlns:x="http://example.org/publishing"
id="333-33-3333"
>
<name>Aaron Skonnard</name>
<address>
<street>123 Main</street>
<zip>84043</zip>
</address>
<phone>801-729-0924</phone>
<phone>801-390-4555</phone>
<phone>801-825-3925</phone>
<recentPublications>
<whitepaper>Web Service Abstractions</whitepaper>
<book>Essential XML Quick Reference</book>
<article>Web Services and DataSets</article>
<article>Understanding SOAP</article>
<book>Essential XML</book>
</recentPublications>
</x:author>
По умолчанию в составных типах есть модели закрытого содержимого (closed
content models). Это означает, что в экземпляре могут появиться только
указанные части. Однако с помощью групповых символов (wildcards) XML
Schema дает возможность определять модель открытого содержимого (open
content model). Использование xsd:any в составном типе
означает, что в этом месте может появиться любой элемент, т.е. он играет роль
структурного нуля для тех элементов, которые вы не можете прогнозировать. Также
вы можете использовать xsd:anyAttribute для определения
структурного нуля для атрибутов.
...
<xsd:complexType name="AuthorType">
<!-- compositor goes here -->
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="phone" type="tns:Phone"/>
<xsd:any minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
<xsd:anyAttribute/>
</xsd:complexType>
<xsd:element name="author" type="tns:AuthorType"/>
...
Следующее иллюстрирует корректный экземпляр элемента author,
описанного выше:
<x:author xmlns:x="http://example.org/publishing"
xmlns:aw="http://www.aw.com/legal/contracts"
aw:auId="01-3424383"
>
<!-- explicitly defined by the complexType -->
<name>Aaron Skonnard</name>
<phone>801-825-3925</phone>
<!-- extra elements that replace wildcard -->
<aw:contract xmlns:aw="http://www.aw.com/legal/contracts">
<title>Essential Web Services Quick Reference</title>
<deadline>2003-06-01</deadline>
</aw:contract>
...
</x:author>
Используя групповые символы, можно также ограничить пространство имен, из
которого фактически происходит содержимое. И xsd:any, и
xsd:anyAttribute поступают с необязательным атрибутом
пространства имен, который может содержать любое значение, из приведенных в
Таблице 4. Это делает возможным быть очень точными относительно происхождения
содержимого, замещающего групповой символ.
| Значение атрибута |
Допустимые элементы |
| ##any |
Любой из любого пространства имен |
| ##other |
Любой не из пространства имен targetNamespace |
| ##targetNamespace |
Любой в пространстве имен targetNamespace |
| ##local |
Любой неопределенный (без пространства имен) |
| Список из n строк |
Любой из пространств имен, представленных в списке |
Таблица 4. Атрибут пространства имен Wildcard
Используя групповые символы, вы также можете определить, как обработчик схемы
должен интерпретировать содержимое группового символа при проверке
достоверности. И xsd:any, и xsd:anyAttribute
поступают с атрибутом processContents, который может принимать
одно из трех значений: lax, strict и
skip. Это значение говорит обработчику, должен ли он
осуществлять проверку достоверности схемы в содержимом, замещающем групповой
символ. Значение strict показывает, что проверка достоверности
содержимого должна проводиться; значение lax
показывает, что обработчик должен осуществить проверку достоверности,
если доступна информация схемы; и значение skip показывает, что
он не должен проверять схему.
Давайте рассмотрим пример, в котором используются эти атрибуты. Схема для
SOAP 1.1 фактически использует групповые символы и оба эти атрибута для
определения структуры элементов soap:Header и
soap:Body:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:tns="http://schemas.xmlsoap.org/soap/envelope/"
targetNamespace="http://schemas.xmlsoap.org/soap/envelope/"
>
...
<xs:element name="Header" type="tns:Header" />
<xs:complexType name="Header" >
<xs:sequence>
<xs:any namespace="##other" minOccurs="0"
maxOccurs="unbounded" processContents="lax" />
</xs:sequence>
<xs:anyAttribute namespace="##other"
processContents="lax" />
</xs:complexType>
<xs:element name="Body" type="tns:Body" />
<xs:complexType name="Body" >
<xs:sequence>
<xs:any namespace="##any" minOccurs="0"
maxOccurs="unbounded" processContents="lax" />
</xs:sequence>
<xs:anyAttribute namespace="##any"
processContents="lax" />
</xs:complexType>
...
</xs:schema>
Согласно схеме, soap:Header может содержать нуль или более
элементов и любое количество атрибутов из любого пространства имен, кроме
targetNamespace, в то время как soap:Body
может содержать нуль или более элементов и любое количество атрибутов вообще из
любого пространства имен. В обоих случаях проверка достоверности должна
производиться только в том случае, если информация схемы доступна во время
выполнения (т.е. необязательная проверка достоверности)). Поскольку нет
возможности предсказать то, что будет помещено в элементы
soap:Header или soap:Body, групповые элементы
предоставляют способ создать гибкую, открытую оболочку для обмена XML
сообщениями.
Размещение и управление схемами
Один из вопросов, который всегда возникает в этот момент - как обработчик XML
Schema размещает необходимые описания схемы для данного экземпляра документа во
время выполнения? Обработчики XML Schema выключают пространства имен экземпляра
документа, чтобы разместить соответствующие схемы, но спецификация XML Schema
точно не определяет, как процессор должен сделать это. Большинство обработчиков
обеспечивают возможность загружать кэш схемы, содержащий все схемы, которые вам
понадобятся, заранее. Затем во время выполнения вы просто указываете обработчику
кэш схемы, таким образом, он может эффективно просматривать необходимые для
конкретного экземпляра схемы.
XML Schema также определяет способ предоставления указателя на местоположение
схемы экземпляра документа. Это делается с помощью атрибута
xsi:schemaLocation, как показано ниже:
<x:author xmlns:x="http://example.org/publishing"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://example.org/publishing pubs.xsd"
>
...
Атрибут xsi:schemaLocation обеспечивает вам возможность
предоставлять список пар имени пространства имен и размещения URI, разделенных
пробелами, который показывает, где искать определенный файл схемы. И опять же,
это только подсказка, и обработчик на самом деле может и не заглядывать туда,
если доступен более эффективный механизм поиска.
Заключение
XML Schema обеспечивает ясную систему типов для XML, способную обеспечивать
многие мощные сервисы. Мы рассмотрели основы описаний XML Schema, включая
определения простых и составных типов. Описания простых типов дают вам
возможность определять произвольные пространства значений для текстовых
элементов и атрибутов. С другой стороны, определение составных типов позволяет
вам организовывать простые типы в структуры.
На самом деле XML Schema имеет намного более широкие возможности, чем мы
здесь рассмотрели. Например, описания составных типов поддерживают наследование
по расширению и ограничению, что дает вам возможность определять иерархии
составных типов способом, который прекрасно преобразовывается в иерархии ОО
классов. Вместо иерархий составных типов также можно использовать технику
подстановки в экземплярах документа. XML Schema также делает возможным
разложение описаний XML Schema на многие файлы и пространства имен, которые
затем могут быть включены и/или импортированы, чтобы увеличить повторное
использование и упростить обслуживание. Однако эти более сложные вопросы лучше
оставить на будущее.
Для получения более подробной информации по XML Schema см. электронную версию
Essential XML Quick Reference
(http://www.develop.com/devresources/dmseries.aspx) (свободно
доступна) — главы XML Schema содержат упрощенные описания и примеры каждой
конструкции и типа данных.
Никакая часть настоящей статьи не может быть воспроизведена или
передана в какой бы то ни было форме и какими бы то ни было средствами, будь то
электронные или механические, если на то нет письменного разрешения владельцев
авторских прав.
Материал, изложенный в данной статье, многократно
проверен. Но, поскольку вероятность технических ошибок все равно существует,
сообщество не может гарантировать абсолютную точность и правильность приводимых
сведений. В связи с этим сообщество не несет ответственности за возможные
ошибки, связанные с использованием статьи.
|
|
| |
|
|
|
|