Введение
Пространства имен — источник большой запутанности XML, особенно для новичков
в этой технологии. Большинство вопросов, получаемых мною от читателей, студентов
и посетителей конференций, в той или иной мере касаются пространств имен. Это,
на самом деле, в некоторой степени непонятно, поскольку появилась Пространства имен в XML-рекомендации
(http://www.w3.org/TR/REC-xml-names/) – одна из самых коротких
спецификаций XML, состоящая из 10 страниц, не включая приложения. Путаница,
однако, касается семантики пространства имен, в отличие от синтаксиса,
описанного спецификацией. Чтобы полностью понять пространства имен XML, вы
должны иметь представление о том, что такое пространство имен, как определяются
пространства имен и как они используются.
Эта статья посвящена ответу на эти три вопроса, как с точки зрения
синтаксиса, так и теоретически. Прочитав эту статью, вы поймете, как
пространства имен влияют на семейство XML-технологий.
Что такое пространство имен?
Пространство имен — это набор имен, в котором все имена уникальны. Например,
имена моих детей можно рассматривать как пространство имен, так же как и
названия корпораций Калифорнии, имена идентификаторов типов С++ или имена
Internet-доменов. Любой логически связанный набор имен, в котором каждое имя
должно быть уникальным, является пространством имен.
Пространства имен облегчают поиск уникальных имен. Представьте, как трудно
было бы назвать вашего следующего ребенка, если бы имя должно было бы быть
уникальным на всей Земле. Помещение уникальности в более ограниченные рамки, как
набор имен моих детей, чрезвычайно все упрощает. Когда я называю своего
следующего ребенка, я учитываю только то, чтобы повторно не использовать имя,
которое я уже использовал для другого своего ребенка. Другие родители могут
выбрать такое же имя, как и я, для одного из своих детей, но эти имена будут
частью различных пространств имен и, следовательно, легко различимы.
Перед тем, как добавить в пространство имен новое имя, администрация
пространства имен должна убедиться, что в пространстве имен такого имени еще
нет. В некоторых сценариях это просто сделать, как, например, в присваивании
имен дочерним элементам. В других — чрезвычайно трудно. Многие современные
Internet-администрации присваивания имен являются хорошим примером. Однако если
упустить это, дублирование имен в конце концов приведет к нарушению пространства
имен и сделает невозможным однозначно ссылаться на определенные имена. Когда это
происходит, набор имен официально больше не считается пространством имен — по
определению пространство имен должно обеспечивать уникальность своих членов.
Самим пространствам имен имена также должны присваиваться с точки зрения
практического применения. Если у пространства имен есть имя, мы можем обращаться
к его членам. Например, на Рис. 1 показаны два пространства имен. Их имена —
Microsoft и AcmeHardware. Обратите внимание, что даже, несмотря на то, что они
содержат несколько одинаковых локальных имен, к ним можно однозначно обращаться
с помощью имен пространств имен, как показано на Рис. 1.
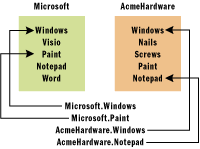
Рис. 1. Однозначные пространства имен
Конечно, это предполагает, что имя пространства имен также уникально. Если
это не может быть гарантировано, сами имена пространства имен также могут быть
помещены в свое собственное пространство имен. Например, если существует
несколько магазинов AcmeHardware (один в Калифорнии, а другой в Юте), помещение
имени AcmeHardware в различные пространства имен решает этот конфликт, как
показано ниже:
California.AcmeHardware.Paint
Utah.AcmeHardware.Paint
Этот шаблон можно повторять столько раз, сколько будет необходимо, чтобы
гарантировать уникальность имен пространств имен. Именно так работает Служба
имен доменов Internet (DNS) — это просто одно большое пространство имен
пространств имен.
Без такого разделения пространства имен, чтобы обеспечить уникальность, вам
придется использовать очень длинные (необычные) имена:
MicrosoftWindowsOperatingSystemPaintApplication
Представьте сложность, а, следовательно, и неудовольствие от работы с одним
глобальным пространством имен, которое не может быть разделено. Ежедневно люди
широко используют пространства имен, хотя, в большинстве ситуаций делают они это
неявно. Однако чтобы использовать пространство имен в разработке программного
обеспечения, необходимо явно объявить его, используя конкретный синтаксис. Перед
тем, как обратимся к пространствам имен в XML, давайте рассмотрим пример
синтаксиса пространства имен в одном из основных современных языков
программирования.
Пространства имен в языках программирования
Чтобы использовать пространства имен в языке программирования, вы должны
хорошо изучить синтаксис определения пространства имен и обращения к чему бы то
ни было в пространстве имен. Многие современные языки, включая C++, Java и C#,
предоставляют поддержку пространств имен. В С++ пространство имен определяется с
помощью блока пространства имен, как показано ниже:
namespace foo1
{
class bar
{
•••
};
class baz
{
•••
};
}
namespace foo2
{
class bar
{
•••
};
class baz
{
•••
};
}
в этом примере определяются два пространства имен, foo1 и foo2, каждое из
которых содержит два имени, bar и baz (которые в данном случае являются
идентификаторами класса).
foo1::bar b1; // ссылается на класс bar в пространстве foo1
foo2::bar b2; // ссылается на класс bar в пространстве foo2
Чтобы обратиться к классу bar определенного пространства
имен, идентификатор bar должен быть определен с идентификатором
данного пространства имен.
Для большего удобства есть также возможность объявить, что вы используете
определенное пространство имен, в установленном исходном файле. Это, по
существу, делает указанное пространство имен для исходного файла одним из
используемых по умолчанию. Затем нет необходимости полностью определять
отдельные члены пространства имен, за исключением, конечно же, случаев, когда
требуется избежать двусмысленности.
using namespace foo1;
bar b1; // ссылается на класс bar в пространстве foo1
Как видите, синтаксис определения и использования пространств имен в С++
прост и понятен. В C# все делается практически точно так же, с некоторыми
небольшими отличиями. Синтаксис использования пространств имен в Java несколько
иной, но концепция та же.
Пространства имен используются во многих языках программирования, чтобы
избегать конфликта имен. Это именно то решение, которое было необходимо для
завершения спецификации XML 1.0.
Пространства имен в XML
Многие разработчики ощущали незавершенность спецификации XML 1.0 (http://www.w3.org/TR/REC-xml), потому
что она не предлагала поддержки для пространств имен. В результате, все имена,
используемые в документах XML, принадлежали одному глобальному пространству
имен, что очень затрудняло подбор уникальных имен.
Большинство разработчиков, включая и самих авторов XML 1.0, знали, что это, в
конечном счете, приведет к слишком большим неоднозначностям в больших
распределенных системах, основанных на XML. Например, ознакомьтесь со следующим
XML-документом:
<student>
<id>3235329</id>
<name>Jeff Smith</name>
<language>C#</language>
<rating>9.5</rating>
</student>
Этот документ использует несколько имен, каждое из которых совершенно
обычное. Элемент student моделирует студента курсов по
программированию. Элементы id, language и
rating образуют номер записи, предпочтительный язык
программирования и рейтинг студента на курсе (10-ти бальная шкала) в базе данных
студентов. Каждое из этих имен, конечно же, будет использоваться в других
ситуациях, где они не несут того же значения.
Например, вот другой XML-документ, который использует те же имена совершенно
по-другому:
<student>
<id>534-22-5252</id>
<name>Jill Smith</name>
<language>Spanish</language>
<rating>3.2</rating>
</student>
В этом случае элемент student моделирует учащегося начальных
классов. Теперь элементы id, language и
rating создают номер социальной страховки, родной язык и
текущий средний балл (4-бальная шкала) ребенка, соответственно. Авторы этих двух
документов для обеспечения уникальности могут использовать более длинные,
необычные имена, но, в конечном итоге, это все равно не гарантирует
уникальности, но усложняет использование.
Хотя люди могут посмотреть и найти различия в этих двух документах, для
программного обеспечения они совершенно одинаковы. Представьте, что вы отвечаете
за построение приложения управления студентами, которое должно поддерживать
много различных XML-документов, касающихся студентов, включая такие, как мы
только что рассмотрели. При написании кода, как вы собираетесь (программно)
различать учащихся ВУЗов и учащихся начальной школы, или любых других учащихся?
Надежного способа сделать это не существует.
Всегда, когда в одном и том же документе или приложении используются элементы
и атрибуты из различных XML-словарей, возникают конфликты имен. Рассмотрите
XSLT, который сам по себе является XML-словарем для определения преобразований.
В данном преобразовании можно вывести определенные пользователем буквенные
элементы. Поэтому, поскольку XSLT-словарь содержит названный шаблон элемента,
как можно было бы вывести определенный пользователем буквенный элемент, который
также является названным шаблоном?
<!— Это шаблонный элемент из XSLT -->
<template match="foo">
<!— Я хочу вывести этот элемент -->
<template match="foo"/>
</template>
Потенциальные возможности конфликта имен стали чрезвычайно очевидными в таких
языках программирования как XSLT и XML Schema, которые сильно смешивают
XML-словари. Однако этих проблем можно избежать, если XML предоставит поддержку
для пространств имен.
Пространства имен в XML-рекомендации – это решение W3C бед с именами в XML
1.0. Эта спецификация определяет, как расширить синтаксис XML 1.0, чтобы
поддерживать пространства имен. Поскольку большинство программистов считают это
дополнение фундаментальным и абсолютно необходимым, часто его признают
официальным дополнением XML 1.0, хотя оно таковым не является. Кстати, сегодня
многие разработчики отказываются использовать просто XML 1.0, а используют "XML
1.0 + пространства имен", по той же причине.
Пространства имен в XML-рекомендации определяют синтаксис для присваивания
имен пространствам имен XML, а также синтаксис обращения к чему бы то ни было в
пространствах имен XML. Однако здесь не касаются вопроса синтаксиса для
определения того, что входит в пространство имен XML. Это было оставлено для
другой спецификации, а именно, для XML Schema. Каждая из этих областей требует
некоторого объяснения.
Присваивание имен пространствам имен
При определении пространства имен в таком языке программирования как С++,
есть ограничения на символы, которые могут использоваться в имени.
Идентификаторы пространства имен XML также должны соответствовать определенному
синтаксису — синтаксису для ссылок Универсального идентификатора ресурса
(Uniform Resource Identifier (URI)). Это значит, что идентификаторы пространства
имен XML должны следовать шаблонному синтаксису для URI, определенному в RFC
2396.
URI определяется как составная строка символов для определения абстрактного
или физического ресурса. В большинстве ситуаций ссылки URI используются для
определения физических ресурсов (Web-страниц, файлов для загрузки и т.д.), но в
случае с пространствами имен XML ссылки URI определяют абстрактные ресурсы, а
именно, пространства имен.
Согласно URI-спецификации, существует две основные формы URI: Унифицированные
указатели информационного ресурса (Uniform Resource Locators (URL)) и
Унифицированные имена информационного ресурса (Uniform Resource Names (URN)).
Любой тип URI может использоваться как идентификатор пространства имен. Ниже
приведен пример двух URL, которые могут использоваться в качестве
идентификаторов пространства имен:
http://www.develop.com/student
http://www.ed.gov/elementary/students
И вот несколько примеров URN, которые также могут использоваться как
идентификаторы пространства имен:
urn:www-develop-com:student
urn:www.ed.gov:elementary.students
urn:uuid:E7F73B13-05FE-44ec-81CE-F898C4A6CDB4
Наиболее важным атрибутом пространства имен является то, что он уникален.
Регистрируя имя домена в Internet-администрации присваивания имен, авторы могут
гарантировать уникальность URL. Затем автор отвечает за обеспечение уникальности
всех строк, используемых после имени домена.
URN работает так же. Вот основной синтаксис URN:
urn:<namespace identifier>:<namespace specific string>
Чтобы гарантировать уникальность URN, авторы снова должны регистрировать
идентификатор пространства имен в Internet-администрации присваивания имен.
Далее автор несет ответственность за следование схеме генерирования уникальных,
характерных для пространства имен строк.
Организации, определяющие пространства имен XML, должны разработать
последовательную схему создания новых имен пространств имен. Например, W3C
постоянно определяет новые пространства имен XML. Они используют довольно
интуитивное правило, в котором используются текущий год и название рабочей
группы. На Рис. 2 показан шаблон, используемый W3C.
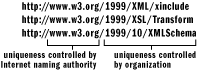
Рис. 2. W3C URI-конструкции
По определению, URI — уникален, т.е. никогда не возникает необходимости
наслаивать дополнительные пространства имен поверх идентификаторов пространств
имен XML. Пока авторы пространств имен гарантируют уникальность идентификаторов
пространств имен, всегда есть возможность уникально идентифицировать что-то в
XML, используя только один классификатор пространства имен. Это сильно упрощает
работу с пространствами имен в XML.
Обработчик XML интерпретирует идентификаторы пространства имен как
непрозрачные строки и никогда как разрешимые ресурсы. Повторяю еще раз:
идентификаторы пространства имен — это просто строки! Два идентификатора
пространств имен считаются идентичными, если она совершенно одинаковы, символ к
символу.
И в завершение, действительно не имеет значения, какой тип ссылки URI вы
решили использовать. Многие разработчики любят использовать URL, потому что они
проще читаются и запоминаются, а другие предпочитают URN из-за их гибкости. Что
бы вы ни выбрали, убедитесь, что вы знаете, как обеспечить
уникальность.
Описание пространств имен
Пространства имен в XML-рекомендациях не обеспечивают синтаксиса для
определения того, что входит в пространство имен. Во многих ситуациях этот тип
синтаксического описания даже не нужен. Сегодня большинство пространств имен XML
определены в формальных документах спецификации, которые описывают имена
элементов, а также атрибутов вместе с их семантикой. Именно так формально
определены все пространства имен W3C (в качестве примера смотрите спецификацию
XSLT 1.0 в http://www.w3.org/TR/xslt).
Как только пространство имен определено, разработчик программного обеспечения
реализовывает пространство имен, как предписывает спецификация. Например, MSXML
3.0, Xalan и Saxon – все это реализации спецификации XSLT 1.0. Эти реализации
жестко запрограммированы на поиск элементов, которые принадлежат пространству
имен XSLT 1.0 (http://www.w3.org/1999/XSL/Transform). Чтобы использовать эти
реализации, вы должны предоставить им XML-документ, который правильно использует
имена из пространства имен XSLT 1.0 (подробнее об этом в следующем разделе).
Если что-то в пространстве имен XSLT 1.0 было изменено, обеспечивающие
программные средства должны быть обновлены.
Рабочая группа XML Schema (http://www.w3.org/XML/Schema) собрала новую
спецификацию (XML Schema), которая определяет синтаксис на базе XML для описания
элементов, атрибутов и типов в пространстве имен. Наконец, XML Schema делает
возможным обеспечить синтаксическое описание для пространства имен, как показано
ниже.
<schema xmlns='http://www.w3.org/2000/10/XMLSchema'
targetNamespace='http://www.develop.com/student'
elementFormDefault='qualified'
>
<element name='student'>
<complexType>
<sequence>
<element name='id' type='long'/>
<element name='name' type='string'/>
<element name='language' type='string'/>
<element name='rating' type='double'/>
</sequence>
</complexType>
</element>
</schema>
В этом примере описывается пространство имен http://www.develop.com/student,
содержащее пять именованных элемента: student, id, name, language и rating.
Кроме простого предоставления пространства имен, эта схема также предоставляет
дополнительные метаданные, такие как порядок дочерних элементов элемента
student, а также их типы.
С такими синтаксическими описаниями пространств имен, как предлагает XML
Schema, можно построить более сложное программное обеспечение, которое
использует имя и информацию о типе во время выполнения. XML Schemas не
определяют семантику элементов и атрибутов и, следовательно, все еще нуждаются в
сопроводительной спецификации. В будущем большинство пространств имен XML будут
определяться как в спецификации, так и в описаниях схемы.
Использование пространств имен
Я определяю использование пространства имен, как процесс использования одного
или более элементов или атрибутов из данного пространства имен в XML-документе.
Определение имен элементов и атрибутов идентификаторами пространства имен
требует понимания синтаксиса, обозначенного Пространствами имен в
XML-рекомендации.
Имена элементов и атрибутов на самом деле образуются из двух частей: имени
пространства имен и локального имени. Такие двойные имена известны как составные
имена или QName.
В XML-документе мы используем префикс пространства имен, чтобы определить
локальные имена элементов или атрибутов. На самом деле, префикс – это просто
аббревиатура идентификатора пространства имен (URI), который обычно слишком
длинный. Сначала префикс преобразовывается в идентификатор пространства имен
через описание пространства имен. Синтаксис описания пространства имен
следующий:
xmlns:<prefix>='<namespace identifier>'
Описание пространства имен выглядит просто как атрибут (элемента), но в
рамках логической структуры документа нет официально принятых атрибутов (т.е.
они не появятся в коллекции атрибутов элемента при использовании DOM).
Префикс пространства имен рассматривается в области видимости элемента
описания, так же как и наследующихся от него элементов. Будучи объявленным,
префикс может использоваться перед именем любого элемента или атрибута,
отделенным от него двоеточием (как s:student). Это полное имя, включая префикс,
является лексической формой составного имени (QName):
QName = <prefix>:<local name>
Префикс ассоциирует элемент или атрибут с идентификатором пространства имен,
в настоящее время преобразованным в префикс в области видимости.
Давайте предположим, что разработчик хочет использовать пространство имен the
XSLT 1.0. Ему понадобится предоставить описание пространства имен, которое
преобразовывает произвольный префикс в официальный идентификатор пространства
имен XSLT 1.0 (http://www.w3.org/1999/XSL/Transform). Затем перед каждым
элементом или атрибутом из пространства имен XSLT 1.0, которые разработчик хочет
использовать, просто надо поставить соответствующий префикс, как показано в
следующем примере:
<x:transform version='1.0'
xmlns:x='http://www.w3.org/1999/XSL/Transform'
>
<x:template match='/'>
<hello_world/>
</x:template>
</x:transform>
Предыдущий пример показывает синтаксис обращения к элементам в пространстве
имен. Каждый элемент, имеющий префикс "x", из пространства имен
http://www.w3.org/1999/XSL/Transform, в то время как любой элемент, не имеющий
префикса, не относится к пространству имен (например, hello_world). Теперь
обработчик может различать программные конструкции XSLT 1.0 и буквенные
элементы, которые предназначены для вывода, как, например, hello_world. Если в
имени пространства имен XSLT 1.0 сделана хотя бы одна ошибка, обработчик XSLT
1.0 не сможет распознать документ как словарь, который он понимает.
По существу, у каждого элемента теперь есть имя, состоящее из двух частей:
идентификатора пространства имен и локального имени. К комбинации этих двух имен
часто обращаются как к имени пространства имен (примечание: в отличие от QName,
которое является комбинацией префикса и локального имени).
Следующий XML-документ показывает, как использовать элементы из описания XML
Schema, показанного ранее:
<d:student xmlns:d='http://www.develop.com/student'>
<d:id>3235329</d:id>
<d:name>Jeff Smith</d:name>
<d:language>C#</d:language>
<d:rating>9.5</d:rating>
</d:student>
Обратите внимание, что независимо от того, как определены пространства имен,
синтаксис обращения к ним одинаковый.
Когда документы используют элементы или атрибуты из нескольких пространств
имен, общепринятым является иметь описания нескольких пространств имен в данном
элементе, как показано в следующем примере:
<d:student xmlns:d='http://www.develop.com/student'
xmlns:i='urn:schemas-develop-com:identifiers'
xmlns:p='urn:schemas-develop-com:programming-languages'
>
<i:id>3235329</i:id>
<name>Jeff Smith</name>
<p:language>C#</p:language>
<d:rating>9.5</d:rating>
</d:student>
Здесь элементы student и rating из одного
пространства имен, id и language из разных, а
name не принадлежит ни одному пространству имен.
Префиксы пространства имен также могут быть изменены путем переобъявления
префикса во вложенном контексте, как показано здесь:
<d:student xmlns:d='http://www.develop.com/student'>
<d:id>3235329</d:id>
<d:name xmlns:d='urn:names-r-us'>Jeff Smith</d:name>
<d:language>C#</d:language>
<d:rating>35</d:rating>
</d:student>
В этом примере все элементы из одного пространства имен, кроме элемента
name, который относится к пространству имен urn:names-r-us. Но
в то время как переобъявить префикс пространства имен можно, нельзя не объявить
его. Например, следующее неверно:
<d:student xmlns:d='http://www.develop.com/student'>
<d:id xmlns:d=''>3235329</d:id>
•••
</d:student>
Префикс-ориентированный синтаксис для обращения в чему бы то ни было в
пространствах имен XML довольно нагляден для большинства разработчиков
программного обеспечения. Если бы Пространства имен в XML-рекомендации
остановились на этом, пространства имен были бы намного менее
запутанными.
Стандартные пространства имен
Есть еще один тип описания пространства имен, который может использоваться
для ассоциирования идентификаторов пространств имен с именами элементов. Они
известен как описание стандартного пространства имен, которое использует
следующий синтаксис:
xmlns='<namespace identifier>'
Обратите внимание, что здесь нет префикса. Когда используется описание
стандартного пространства имен, все неопределенные имена элементов автоматически
ассоциируются с установленным идентификатором пространства имен. Однако описания
стандартных пространств имен абсолютно никак не влияют на атрибуты. Единственный
способ ассоциировать атрибут с идентификатором пространства имен — через
префикс.
Рассмотрим следующий пример:
<d:student xmlns:d='http://www.develop.com/student'
xmlns='urn:foo' id='3235329'
>
<name>Jeff Smith</name>
<language xmlns=''>C#</language>
<rating>35</rating>
</d:student>
Здесь "student" из пространства имен
http://www.develop.com/student, а "name" и
"rating" из стандартного пространства имен urn:foo. Атрибут
id не принадлежит пространству имен, поскольку атрибуты
автоматически не ассоциируются с идентификатором стандартного пространства
имен.
Этот пример также иллюстрирует, что вы можете отменить объявление
стандартного пространства имен, просто установив его идентификатор опять в
пустую строку, как показано в элементе language (помните, что
вы не можете делать этого с описаниями префиксов). В результате элемент
language также не принадлежит пространству имен.
Синтаксис стандартных пространств имен был разработан для удобства, но принес
больше вреда, чем пользы. Обычно трудности вызывает тот факт, что элементы и
атрибуты по-разному интерпретируются и не сразу видно, что вложенным элементам
присвоен идентификатор стандартного пространства имен. Тем не менее, в конце
концов, выбор между префиксами и стандартными пространствами имен — это,
преимущественно, вопрос стиля, за исключением случаев, когда начинают
действовать атрибуты.
Абстракции пространства имен
Работать с пространствами имен с абстрактной точки зрения XML-документа
намного проще, чем работать с только что описанными лексическими проблемами.
Информационное множество XML (Infoset) определяет абстрактную структуру
XML-документа, которая защищает разработчиков от сложностей формата базовой
сериализации, как только что описанный синтаксис пространства имен.
Согласно Infoset, у каждого элемента или атрибута есть два свойства имени:
идентификатор пространства имен и локальное имя. На Рис. 3 показана логическая
структура XML-документа, который содержит имена, определенные пространством
имен. Обратите внимание, что элементы student,
id и language — из одного пространства имен,
ratings — из другого, а name вообще не принадлежит ни одному
пространству имен. Этот документ может быть сериализован через использование
технологий, описанных в предыдущих разделах.
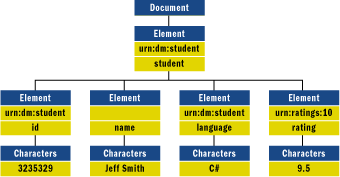
Рис. 3. Определенный пространством имен XML-документ
Рассмотрим как широко распространенные сегодня API, SAX и DOM реализовывают
эту абстрактную модель данных. SAX создает элементы с помощью вызовов метода
startElement/endElement в ContentHandler:
public interface contentHandler
{
•••
void startElement(String namespaceURI, String localName,
String qName, Attributes atts) throws SAXException;
void endElement(String namespaceURI, String localName,
String qName) throws SAXException;
•••
}
Обратите внимание, что элементы идентифицируются комбинацией идентификатора
пространства имен и локального имени (и, не обязательно, QName). Атрибуты также
идентифицируются через ряд знающих пространство имен методов интерфейса
Attributes. Это говорит о том, что при использовании SAX программно различить
различные типы элементов student нетрудно.
•••
void startElement(String namespaceURI, String localName,
String qName, Attributes atts)
{
if ( namespaceURI.equals("urn:dm:student") &&
localName.equals("student") )
{
// обрабатываем элемент student из пространства имен urn:dm:student
}
else if ( namespaceURI.equals("urn:www.ed.gov:student")
&& localName.equals("student") )
{
// обрабатываем элемент student из пространства имен urn:www.ed.gov:student
}
}
•••
Поскольку имя пространства имен (идентификатор пространства имен + локальное
имя) автоматически разбирается синтаксическим анализатором SAX, не имеет
значения, какой префикс (если он имеется) использовался в конкретном элементе
или атрибуте исходного документа — это, по большей мере, деталь сериализации.
Однако это не значит, что префиксы после синтаксического анализа могут быть
отброшены. Рассмотрим следующий XML документ:
<student xmlns:xsd='http://www.w3.org/2000/10/XMLSchema'
xmlns:xsi='http://www.w3.org/2000/10/XMLSchema-instance'
>
<age xsi:type='xsd:double'>35.0</age>
</student>
Обратите внимание, что атрибут XML Schema xsi:type элемента
age содержит значение QName. Когда бы QName ни использовался в
содержимом элемента или атрибута, необходимо, чтобы использующее приложение
работало с ним вручную. Приложение может интерпретировать это значение правильно
только в одном случае — если оно знает, чем ограничен идентификатор пространства
имен "xsd". По этой причине Infoset также поддерживает набор описаний
пространств имен которые находятся в области видимости для каждого элемента в
документе. SAX формирует эту информацию через вызовы методов startPrefixMapping
и endPrefixMapping.
DOM API — это другая реализация Infoset. Его интерфейс Node формирует базовую
идентичность узлов элемент/атрибут посредством двух свойств имени: namespaceURI
и localName. Он также моделирует QName и префикс узла через свойства nodeName и
prefix. Приведенный ниже код на Java иллюстрирует то, как, используя DOM, вы
можете различить два разных элемента student.
void processStudent(Node n)
{
if ( n.getNamespaceURI().equals("urn:dm:student") &&
n.getLocalName().equals("student") )
{
// обрабатываем элемент student из пространства имен urn:dm:student
}
else if (
n.getNamespaceURI().equals("urn:www.ed.gov:student")
&& n.getLocalName().equals("student") )
{
// обрабатываем элемент student из пространства имен urn:www.ed.gov:student
}
}
Как и в SAX, синтаксический анализатор XML, который строит DOM дерево,
отвечает за соответствующее заполнение свойств пространства имен. И вновь, если
вы работаете с логической структурой документа, то, как были объявлены
пространства имен в исходном документе, не имеет значения. Если вы создаете
документ через DOM API, тогда за обеспечение идентификаторов пространства имен
для каждого элемента и атрибута при создании отвечаете вы:
void generateStudentDocument(Document doc)
{
Node docEl = doc.createElementNS("urn:dm:student", "student");
doc.appendChild(docEl);
Node n = doc.createElementNS("", "name");
docEl.appendChild(n);
•••
}
Как видите, этот код дает вам возможность прямо создать логическую структуру.
Затем, это уже дело реализации DOM определить, как сериализовать описания
пространства имен в базовый XML 1.0-документ. Это конкретное DOM-дерево может
быть сериализовано следующим образом:
<student xmlns='urn:dm:student'>
<name xmlns=''/>
</student>
Когда вы имеете дело с абстрактным видом XML-документа (через SAX/DOM API),
важно обратить внимание, что здесь нет понятия стандартного пространства имен. В
предыдущем примере после обращения к createElementNS для получения
"student" urn:dm:student не превращается в стандартное
пространство имен. Вызов "name" в createElementNS без
пространства имен присваивает пустой идентификатор пространства имен элементу
name (не urn:dm:student). То же применимо к SAX с учетом
последовательности вызовов метода startElement/endElement. Каждый узел
элемент/атрибут всегда интерпретируется независимо относительно информации
name.
XPath —другая XML-спецификация, которая определяет, как идентифицировать узлы
в абстрактной структуре документа. Выражения XPath делают возможным
идентифицировать элементы и атрибуты по определенным пространством имен именам.
Поскольку проверки имен XPath — это простые строковые выражения, единственным
способом ассоциировать проверку имени XPath с идентификатором пространства имен
является использование префикса пространства имен.
Вы можете подумать, что проверки узлов XPath — это что-то вроде QName. Это
значит, что, если узел не содержит префикс, он как будто запрашивает данное имя,
которое принадлежит "никакому пространству имен". Например, возьмем следующее
выражение XPath:
Это выражение идентифицирует все элементы name, которые не
принадлежат ни одному пространству имен и являются потомками корневого элемента
student, который не относится ни к одному пространству имен.
Чтобы идентифицировать элементы student и
name, принадлежащие пространству имен urn:dm:student, сначала
необходимо ассоциировать префикс пространства имен с urn:dm:student. Затем этот
префикс может использоваться в выражении XPath.
Принимая, что "dm" был ассоциирован с urn:dm:student в
контексте XPath, теперь следующее выражение будет идентифицировать элементы
name, принадлежащие пространству имен urn:dm:store и являющиеся
потомками корневого элемента student, также принадлежащего
пространству имен urn:dm:store:
Если запрашиваемый документ выглядит как приведенный ниже код, тогда
предыдущее выражение будет идентифицировать все элементы name дерева, являющиеся
потомками student, независимо от их префикса, потому что все они из одного
рассматриваемого пространства имен.
<s:student xmlns:s='urn:dm:student'>
<s:name/>
<n:name xmlns:n='urn:dm:student'/>
<s:name/>
</s:student>
Префиксы преобразовываются в контекст XPath в зависимости от реализации
(более подробно об этом в MSXML 3.0 см. в XML-файлы
(http://msdn.microsoft.com/webservices/understanding/xmlfundamentals/default.aspx?pull=/library/en-us/dnmag01/html/xml0105.
asp)
за май 2001). Одним из примеров этого является XSLT, который предоставляет
контекст для использования XPath-выражений. Чтобы использовать определенные
пространством имен XPath-выражения в XSLT-документе, для преобразования
заданного идентификатора пространства имен в произвольный префикс может
использоваться стандартное описание пространства имен.
<x:transform version='1.0'
xmlns:x='http://www.w3.org/1999/XSL/Transform'
xmlns:d='urn:dm:student'
>
<x:template match='d:student'>
<!-- transform student here -->
<x:apply-templates select='d:name'/>
</x:template>
•••
</x:transform>
Обратите внимание, что первый шаблон совпадает с элементом
student из пространства имен urn:dm:student. Если совпадающее
значение было бы просто "student", он бы просто совпадал с
элементами student, не принадлежащим никакому пространству
имен. Затем элемент apply-templates обрабатывает все дочерние
элементы name, которые тоже принадлежат пространству имен
urn:dm:student.
Как видите, понимание того, как лексически и абстрактно работают пространства
имен, важно для понимания всего семейства XML-спецификаций. Вы столкнетесь со
многими подобными этой ситуациями в XML-спецификациях.
Заключение
Пространство имен — это набор имен, в котором все имена уникальны.
Пространства имен в XML позволяют присваивать уникальные имена элементам и
атрибутам. Хотя пространства имен являются источником многих сложностей, они
просты для понимания, если вы хорошо знакомы с тем, как они определяются и
используются, как синтаксически, так и абстрактно. Для получения более подробной
информации по пространствам имен смотрите Пространства
имен в XML-рекомендации (Namespaces in XML Recommendation)
(http://www.w3.org/TR/REC-xml-names/) и Пространства имен XML в примерах (XML Namespaces by Example)
(http://www.xml.com/pub/a/1999/01/namespaces.html).
Никакая часть настоящей статьи не может быть воспроизведена или
передана в какой бы то ни было форме и какими бы то ни было средствами, будь то
электронные или механические, если на то нет письменного разрешения владельцев
авторских прав.
Материал, изложенный в данной статье, многократно
проверен. Но, поскольку вероятность технических ошибок все равно существует,
сообщество не может гарантировать абсолютную точность и правильность приводимых
сведений. В связи с этим сообщество не несет ответственности за возможные
ошибки, связанные с использованием статьи.